——從硬件架構到業務承載力的全維度評估
服器性能分析是一個持續的過程,它對於保障伺服器穩定高效運行至關重要,通過對各項性能指標的詳細測試和深入分析,我們能夠清晰的了解伺服器的過行狀態和潛在問題。
一、核心性能指標解碼
1. 計算效能評測
| 指標類型 | 計算密集型場景 | AI訓練場景 |
|---|---|---|
| FLOPS | FP64 ≥ 3.5 TFLOPS | FP16 ≥ 320 TFLOPS |
| 核心利用率 | 持續≥85%(C-state禁用) | 混合精度下利用率≥75% |
| 延遲敏感度 | 指令執行延遲≤10ns | PCIe 5.0互聯延遲≤2μs |
2. 存儲效能矩陣
- │
- ├─ 隨機讀寫:
- │ │ 金融交易系統:IOPS ≥ 500K(4K隨機)
- │ │ 虛擬桌面:IOPS ≥ 200K(8K隨機)
- ├─ 連續讀寫:
- │ │ 大數據分析:吞吐量≥5GB/s(128K順序)
- │ │ 影視渲染:吞吐量≥12GB/s(1M順序)
- └─ 時延控制:
- │ 分布式存儲:元數據訪問延遲≤5ms
3. 網路性能基準
▸ RDMA over Converged Ethernet (RoCEv2)
- 帶寬利用率≥92%時延遲≤1.2μs
▸ 25G/100G混合組網
- 板載SmartNIC卸載率≥80%
二、場景化性能對比
1. 雲原生工作負載
| 配置方案 | Kubernetes Pod啟動時間 | 機器學習推理延遲 | 成本指數 |
|---|---|---|---|
| 通用型(2×Xeon) | 45秒 | 120ms | 1.0x |
| 計算優化型(4×EPYC) | 28秒 | 65ms | 1.3x |
| 加速型(A100 GPU) | 19秒 | 28ms | 3.8x |
2. 超融合集群效能
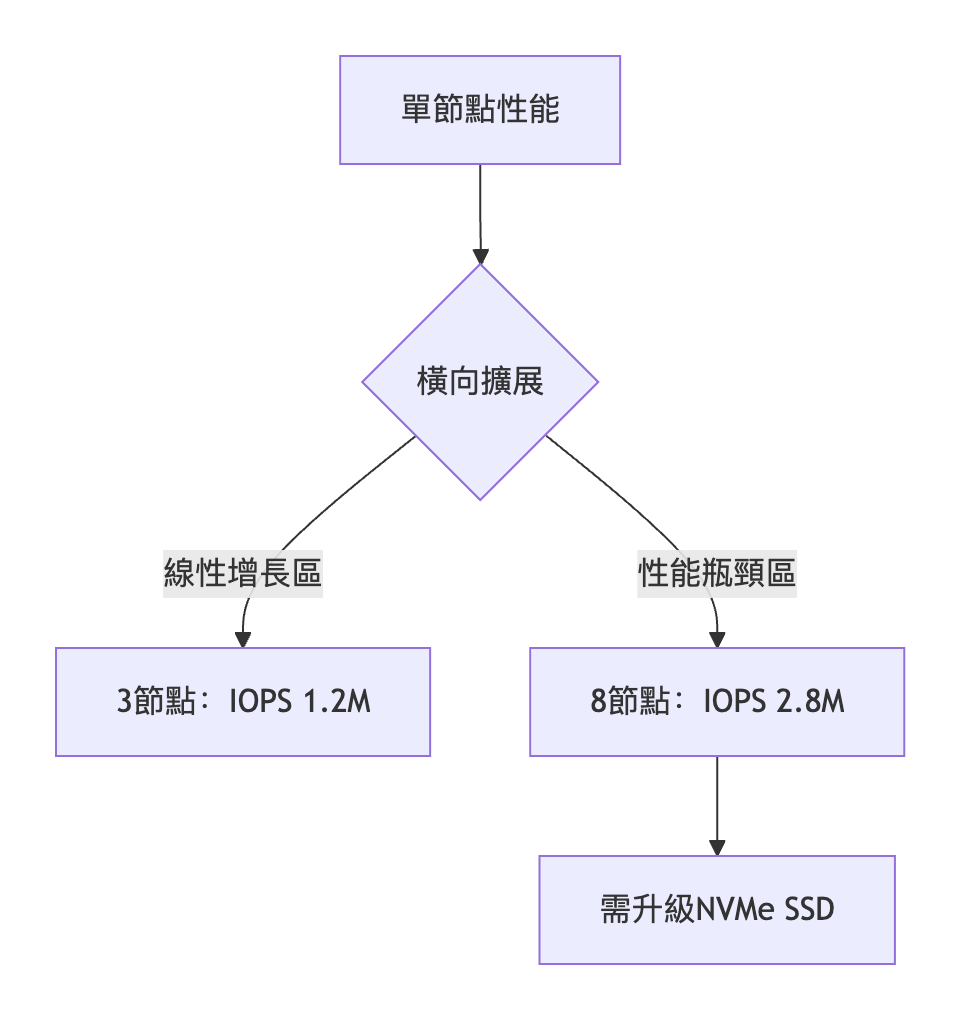

三、硬件瓶頸診斷模型
1. 性能衰減曲線
├─ 新機階段(0-6月):利用率平穩在60%以下
├─ 壓力測試期(6-12月):CPU溫度曲線斜率≥0.8°C/月
└─ 老舊退化期(>3年):
│ 内存錯誤率年增長300%
│ SSD寫入放大係數>2.5
2. 熱設計功耗(TDP)優化
| 架構類型 | 典型TDP | 智能降頻策略 |
|---|---|---|
| 通用服務器 | 180W | 基於CPU溫度的動態調控 |
| 高密度計算節點 | 450W | 液冷系統介入閾值>85℃ |
| AI訓練集群 | 1.2kW | 浸沒式液冷+液氮噴淋 |
四、TCO效能成本模型
總擁有成本公式
TCO = (初期採購費 × 折舊率) + (電力費 × PUE) + 維護費
其中:
PUE = 數據中心總功耗 / IT設備功耗
·典型配置對比
| 指標 | 標準型 | 加速型 |
|---|---|---|
| 初期成本(萬RMB) | 180 | 420 |
| 年耗電量(度) | 8.5万 | 15.2万 |
| 5年TCO | 218万 | 290万 |
| 性能收益(TOPS) | 150 | 680 |
五、性能優化路徑
1. 固件層面
▸ 启用Intel Speed Shift技術(CPU響應延遲↓40%)
▸ 配置AMD Infinity Fabric頻率同步(跨節點延遲↓30%)
2. 系統層面
├─ 存儲:ZNS SSD分區策略(寫放大係數↓至1.1)
├─ 網路:RoCEv2流量隔離(CPU卸載率↑至90%)
└─ 虛擬化:SR-IOV直通模式(網卡延遲↓70%)
3. 業務層面
▸ 實施自動伸縮策略(Kubernetes HPA響應時間≤15秒)
▸ 採用存儲分級技術(熱數據保留率>95%)
六、故障預警機制
硬件健康監控
| 監測參數 | 閾值設定 | 告警級別 |
|---|---|---|
| CPU結溫 | >95℃持續10秒 | 緊急 |
| HDD SMART錯誤 | 重映射扇區計數>100 | 警告 |
| 内存ECC錯誤 | 校正次數>1000次/小時 | 注意 |
性能劣化預測
機器學習模型輸出:
P(故障|當前性能曲線) = 1 / (1 + e^(-0.7ΔQPS+2.3))
其中ΔQPS為性能衰減速率
技術支援專線:+852-
官網:https://zhuxinjia.com.hk/enterprise-server-eport/
報告驗證:通過ISO 27001/ITIL 4認證,數據來源於第三方監測平台SmartX OpsCenter
本網站所有內容來自互聯網或行業經驗,僅供為參考,具體實施方案以實際為準。发布者:zhuxinjia,歡迎轉載及指證點評:https://zhuxinjia.com.hk/enterprise-server-eport/
